Next: Speex wideband mode (sub-band Up: The Speex Codec Manual Previous: Introduction to CELP Coding Contents Index
This section looks at how Speex works for narrowband (
![]() sampling rate) operation. The frame size for this mode is
sampling rate) operation. The frame size for this mode is
![]() ,
corresponding to 160 samples. Each frame is also subdivided into 4
sub-frames of 40 samples each.
,
corresponding to 160 samples. Each frame is also subdivided into 4
sub-frames of 40 samples each.
Also many design decisions were based on the original goals and assumptions:
In narrowband, Speex frames are 20 ms long (160 samples) and are subdivided
in 4 sub-frames of 5 ms each (40 samples). For most narrowband bit-rates
(8 kbps and above), the only parameters encoded at the frame level
are the Line Spectral Pairs (LSP) and a global excitation gain ![]() ,
as shown in Fig. 3. All other parameters
are encoded at the sub-frame level.
,
as shown in Fig. 3. All other parameters
are encoded at the sub-frame level.
Linear prediction analysis is performed once per frame using an asymmetric
Hamming window centered on the fourth sub-frame. Because linear prediction
coefficients (LPC) are not robust to quantization, they are first
are converted to line spectral pairs (LSP).
The LSP's are considered to be associated to the ![]() sub-frames
and the LSP's associated to the first 3 sub-frames are linearly interpolated
using the current and previous LSP coefficients. The LSP coefficients
and converted back to the LPC filter
sub-frames
and the LSP's associated to the first 3 sub-frames are linearly interpolated
using the current and previous LSP coefficients. The LSP coefficients
and converted back to the LPC filter
![]() . The non-quantized
interpolated filter is denoted
. The non-quantized
interpolated filter is denoted ![]() and can be used for the weighting
filter
and can be used for the weighting
filter ![]() because it does not need to be available to the decoder.
because it does not need to be available to the decoder.
To make Speex more robust to packet loss, no prediction is applied on the LSP coefficients prior to quantization. The LSPs are encoded using vector quantizatin (VQ) with 30 bits for higher quality modes and 18 bits for lower quality.
The analysis-by-synthesis (AbS) encoder loop is described in Fig.
4. There are three main aspects where Speex
significantly differs from most other CELP codecs. First, while most
recent CELP codecs make use of fractional pitch estimation with a
single gain, Speex uses an integer to encode the pitch period, but
uses a 3-tap predictor (3 gains). The adaptive codebook contribution
![]() can thus be expressed as:
can thus be expressed as:
Many current CELP codecs use moving average (MA) prediction to encode
the fixed codebook gain. This provides slightly better coding at the
expense of introducing a dependency on previously encoded frames.
A second difference is that Speex encodes the fixed codebook gain
as the product of the global excitation gain ![]() with a sub-frame
gain corrections
with a sub-frame
gain corrections ![]() . This increases robustness to packet
loss by eliminating the inter-frame dependency. The sub-frame gain
correction is encoded before the fixed codebook is searched (not closed-loop
optimized) and uses between 0 and 3 bits per sub-frame, depending
on the bit-rate.
. This increases robustness to packet
loss by eliminating the inter-frame dependency. The sub-frame gain
correction is encoded before the fixed codebook is searched (not closed-loop
optimized) and uses between 0 and 3 bits per sub-frame, depending
on the bit-rate.
The third difference is that Speex uses sub-vector quantization of the innovation (fixed codebook) signal instead of an algebraic codebook. Each sub-frame is divided into sub-vectors of lengths ranging between 5 and 20 samples. Each sub-vector is chosen from a bitrate-dependent codebook and all sub-vectors are concatenated to form a sub-frame. As an example, the 3.95 kbps mode uses a sub-vector size of 20 samples with 32 entries in the codebook (5 bits). This means that the innovation is encoded with 10 bits per sub-frame, or 2000 bps. On the other hand, the 18.2 kbps mode uses a sub-vector size of 5 samples with 256 entries in the codebook (8 bits), so the innovation uses 64 bits per sub-frame, or 12800 bps.
There are 7 different narrowband bit-rates defined for Speex, ranging from 250 bps to 24.6 kbps, although the modes below 5.9 kbps should not be used for speech. The bit-allocation for each mode is detailed in table 3. Each frame starts with the mode ID encoded with 4 bits which allows a range from 0 to 15, though only the first 7 values are used (the others are reserved). The parameters are listed in the table in the order they are packed in the bit-stream. All frame-based parameters are packed before sub-frame parameters. The parameters for a certain sub-frame are all packed before the following sub-frame is packed. Note that the ``OL'' in the parameter description means that the parameter is an open loop estimation based on the whole frame.
|
So far, no MOS (Mean Opinion Score) subjective evaluation has been performed for Speex. In order to give an idea of the quality achievable with it, table 4 presents my own subjective opinion on it. It sould be noted that different people will perceive the quality differently and that the person that designed the codec often has a bias (one way or another) when it comes to subjective evaluation. Last thing, it should be noted that for most codecs (including Speex) encoding quality sometimes varies depending on the input. Note that the complexity is only approximate (within 0.5 mflops and using the lowest complexity setting). Decoding requires approximately 0.5 mflops in most modes (1 mflops with perceptual enhancement).
This section was only valid for version 1.1.12 and earlier. It does not apply to version 1.2-beta1 (and later), for which the new perceptual enhancement is not yet documented.
This part of the codec only applies to the decoder and can even be
changed without affecting inter-operability. For that reason, the
implementation provided and described here should only be considered
as a reference implementation. The enhancement system is divided into
two parts. First, the synthesis filter
![]() is replaced
by an enhanced filter:
is replaced
by an enhanced filter:
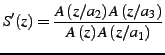
where
![\includegraphics[width=0.35\paperwidth]{speex_analysis}](img53.png)
![\includegraphics[width=0.4\paperwidth]{speex_abs}](img54.png)